
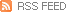
오늘은 2019 ICLR에 발표된 Network Pruning 관련 논문 중 하나인 "Rethinking the Value of Network Pruning"을 리뷰하도록 하겠습니다.
흔히 Neural Network Pruning은 1. Training, 2. Pruning, 3. Fine-tuning 세 과정을 거쳐 이루어집니다. One-shot pruning의 경우에는 1->2->3의 과정을 한 번만 거치게 되고, Iterative pruning의 경우에는 1 이후에 2와 3의 과정을 원하는 모델 사이즈에 도달할 때까지 반복하게 되죠.
이 논문에서는 이렇게 우리가 흔히 알고 있는 pruning 방식, 즉 먼저 큰 모델(Full model, overparameterized)을 학습시킨 다음에 필요 없는 연결을 제거하고 다시 재학습시키는 방식이 애초에 작은 모델을 scratch부터 학습시키는 것과 비슷한 성능을 내거나, 오히려 저하시킬 수 있다고 주장합니다.
이 논문에서 실험을 통해 밝혀낸 3개의 insight를 정리하자면 다음과 같습니다.
1. 애초에 크고 파라미터가 많은 모델을 학습시키는 것이 필요하지 않다.
2. 큰 모델에서 특정 기준을 통해 골라진 weight는 작은 모델에게 필요하지 않다.
3. pruning을 통해 얻은 모델 구조 그 자체가 weight 값보다 더 중요하다.
한마디로 말하면, pruning의 의미는 중요한 weight를 얻는 것이 아니라 architecture를 찾는 것에 있기 때문에, 애초에 큰 모델을 학습시키고 그 weight를 보존할 필요가 없고 작은 모델을 random initialization부터 학습시키는 것이 더 낫다는 이야기입니다. 저자들은 여러 실험을 통해 이 가설이 성립함을 보여주었습니다.
Methodology
1. Predefined vs. Automatic

저자들은 여러 pruning 방식을 두 가지 범주로 분류했습니다. 첫번째는 'predefined' 방식인데요 각 layer에서 얼마 만큼의 channel을 잘라낼 것인지를 미리 정의하는 방식입니다. 따라서 각 layer의 channel 개수가 모두 동일하고, pruning을 모델의 구조를 찾기 위한 도구로 보면 별 의미가 없는 방식입니다.
한편 두번째 방식인 'automatic'은 architecture search의 의미를 가질 수 있습니다. 알고리즘이 각 layer에서 얼만큼의 channel을 제거할지를 자동으로 결정하기 때문입니다. 대표적으로 모든 layer의 batch normalization parameter $\gamma$를 정렬하는 network slimming이 있습니다. filter 혹은 channel을 완전히 제거하는 structured pruning 방식 외에, weight를 sparse하게 만드는 unstructured pruning 방식도 이 범주에 포함됩니다. 대표적으로는 Han et al. 이 2015년에 발표한 weight pruning이 있습니다.
2. Training Budget
본격적으로 실험 결과를 보여드리기 전에, 이 논문에서 제시한 두 가지 모델을 먼저 정의하고 넘어가겠습니다. pruning 이후의 모델 구조가 주어지면, scratch부터 이를 얼마나 학습시켜야 할까요? 저자들은 이에 대해 두 가지 방식을 제안했습니다.
1. Scratch-E
- pruned model을 처음 큰 모델을 학습시킬 때와 같은 epoch만큼 학습시킵니다.
2. Scratch-B
- 처음 큰 모델을 학습시킬 때와 같은 training budget(연산량)를 사용합니다. pruned model은 처음 모델보다 파라미터 개수와 flops가 적을 테니 더 많은 epoch을 사용할 수 있게 되겠죠.
Experiments
Predefined Structured Pruning
- L1-norm based Filter Pruning (Li et al., 2017)
- a certain percentage of filters with smaller L1-norm will be pruned
- ThiNet (Luo et al., 2017)
- greedily prunes the channel that has the smallest effect on the next layer’s activation values

Automatic Structured Pruning
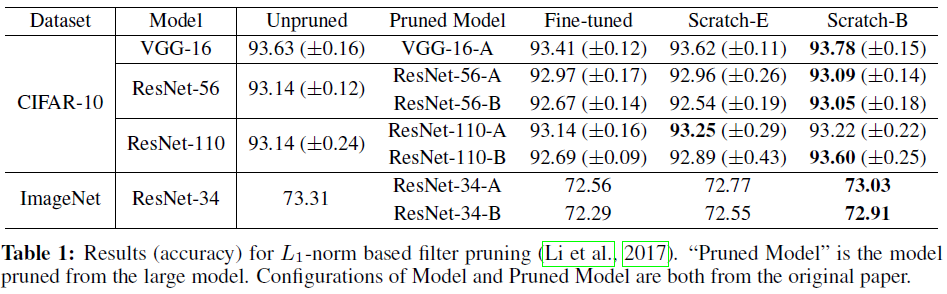
- Network Slimming (Liu et al., 2017)
- L1-sparsity on channel-wise scaling factors from Batch Normalization layers
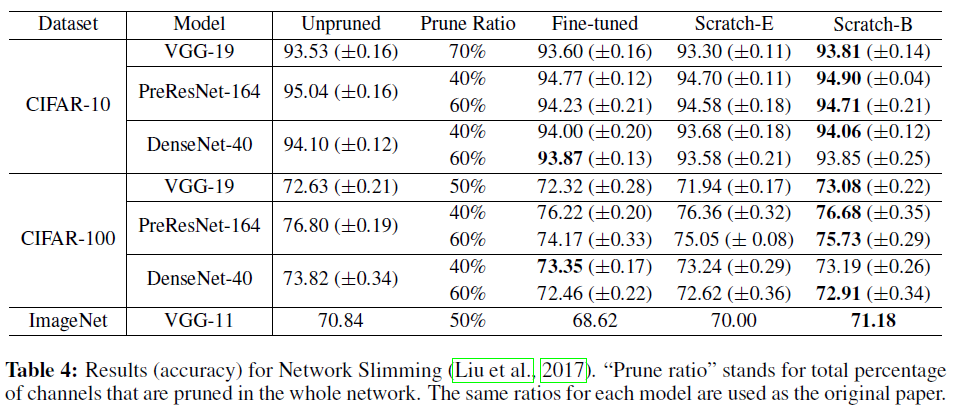
- Sparse Structure Selection (Huang & Wang, 2018)
- also uses sparsified scaling factors to prune structures, and can be seen as a generalization of Network Slimming
Unstructured Pruning
- Weight Pruning (Han et al., 2015)
- L1-sparsity on channel-wise scaling factors from Batch Normalization layers
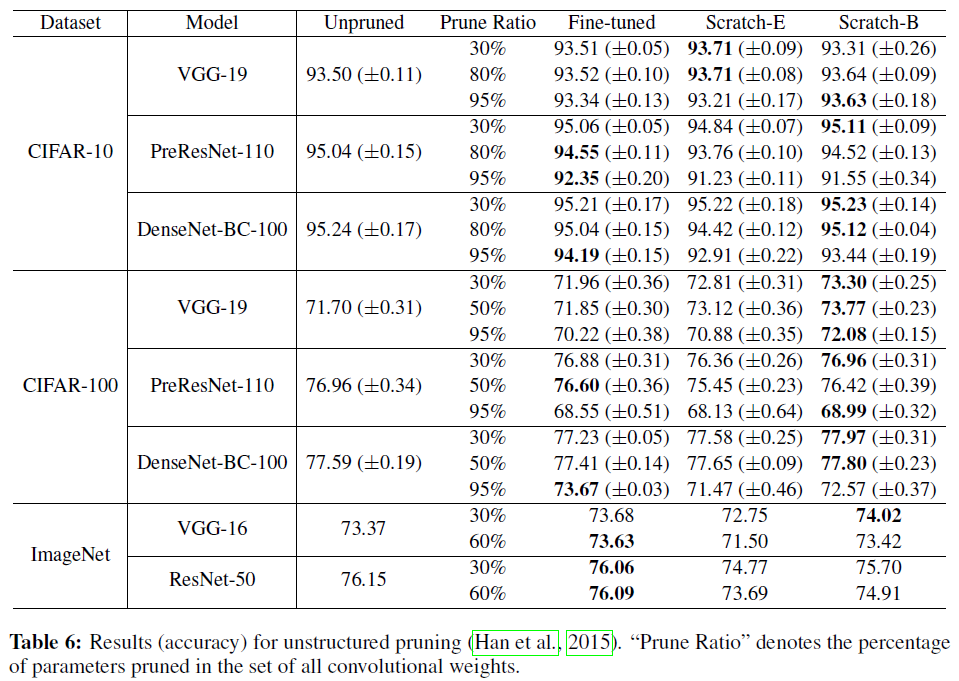
위의 실험 결과를 보시면 CIFAR 데이터셋에서 pruning 비율이 클 때(95%)에는 fine-tuning 결과가 scratch 결과보다 더 나을 때가 많다는 것을 알 수 있습니다. 또한 ImageNet과 같은 큰 데이터셋에서는, 대부분의 경우 Scratch-B가 fine-tuned보다 꽤 저조한 성능을 보입니다. 저자들은 이에 대한 이유로 두 가지 가설을 제시했습니다. 1. network가 굉장히 sparse하거나 (CIFAR), 데이터셋이 크고 복잡할 경우 (ImageNet)에는 모델을 처음부터 학습시키는 것이 어렵고, 2. unstructured pruning이 위의 structured pruning과 비교하여 weight의 분포를 더욱 많이 변화시키기 때문입니다.
Network Pruning as Architecture Search
앞서 말씀드린 대로 저자들의 주장은 pruning의 진정한 의미는 효울적인 네트워크의 구조를 찾는 것에 있다는 것입니다. 이를 증명하기 위해 각 layer의 channel을 같은 비율로 잘라낸 모델(uniform pruning)과 성능을 비교했습니다. 특히 channel pruning의 경우 모든 경우에서 network slimming 모델이 uniform pruning 모델보다 좋은 성능을 보였습니다.

