LLM Evaluators Recognize and Favor Their Own Generations (NeurIPS 2024, Oral)
안녕하세요, KDST팀 이원준입니다.
금일 진행한 세미나에 대해서 공유드리도록 하겠습니다.
NeurIPS 2024에서 Oral Paper로 선정된 논문입니다.
LLM이 발전하면서 LLM으로 evaluation을 진행하는 비중이 많아졌습니다.
이러한 LLM의 역할이 많아짐과 동시에 LLM이 특정한 bias를 가질 수 있다라는게 논문에서 지적하는 포인트입니다.
구체적으로, LLM은 LLM 스스로가 생성한 아웃풋에 대해서 다른 LLM이나 인간이 작성한 텍스트보다 자신의 출력을 더 높게 평가한다라는 것입니다.
논문의 주요 Contribution은 아래와 같습니다.
- LLMs는 self-preference를 가진다
- LLMs는 이러한 self-preference의 이유로 self-recognition 능력이 존재한다.
- Fine-tuning을 통해 self-recognition 능력을 향상시킴으로써 self-preference와의 관계를 증명한다.
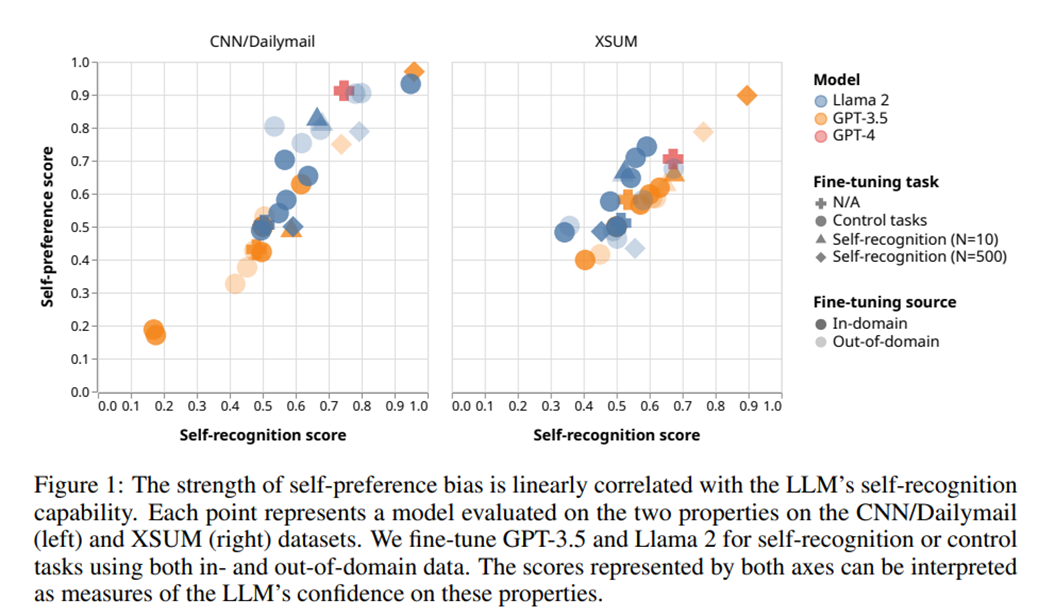
여기에서 self-recognition과 self-preference score 측정 방법은 아래와 같습니다.
- Pairwise measurement
- LLM은 두 개의 텍스트로 구성되어 있으며, 하나는 해당 모델에 의해 생성된 텍스트이고, 다른 하나는 다른 LLM 또는 사람에 의해 생성된 텍스트입니다.
- LLM에게 어떤 문장이 high-quality를 가진 텍스트인지 선택(self-preference)와 어떤 텍스트가 자신이 생성한 텍스트인지 선택(self-recognition)
- LLM의 순서 편향을 피하기 위해, 본 논문에서는 옵션을 교환하고 두 신뢰 점수의 평균을 계산하여 각 예제에 대해 LLM을 두 번 계산합니다.
- 두 옵션과 관련된 토큰의 출력 확률을 정규화하여 예측 신뢰도를 계산합니다
- Individual measurement
- LLM에게 해당 모델에 의해 생성한 텍스트 또는 다른 LLM 또는 사람이 주어진 문장 하나만 주어집니다.
- self-recognition에 대해서는 이 문장이 본인이 생성한 문장인지에 대해서 yes/no로 답변하도록 합니다.
- sefl-preference에 대해서는 이 문장의 퀄리티를 1-5점 스케일로 답변하도록 합니다.
- 두 방식 모두 동일하게 아웃풋 토큰의 확률을 구해서 Normalization을 진행함으로써 점수를 비교합니다.


해당 두 실험을 통해 확연히 사람이 생성한 텍스트에 비해 본인이 생성한 텍스트를 잘 인지하는 결과를 보이고, 더 낫다라는 평가를 내리고 있습니다. 여기에서 score가 높을수록 본인이 생성한 결과가 더 낫다(self-preference) 혹은 잘 인지한다(self-recognition)을 의미합니다.
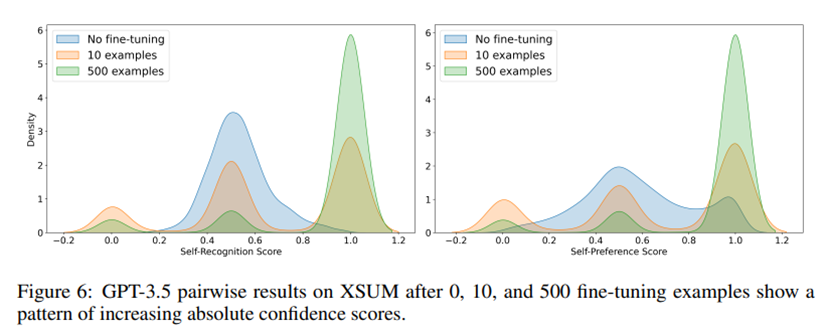

Figure 6. 본 논문에서는 Fine-tuning에 따라 self-recognition의 능력이 변화함에 따라 self-preference 능력도 선형적으로 증가함을 보여줍니다.
Figure 7. Fine-tuning을 일부 한 데이터셋에 적용하더라도, 다른 데이터셋에 대해서도 이러한 self-recognition과 self-preference의 능력이 동일하게 비례하다라는 결과를 보여주는 실험입니다.
Figure 1에서 Control tasks의 경우 Fine-tuning에 따라 영향을 미치는지에 대해서 조사하기 위해 self-recognition과 관련이 없는 task( length, vowel count, and Flesh-Kincaid readability score)로 fine-tuning을 한 것을 의미합니다.
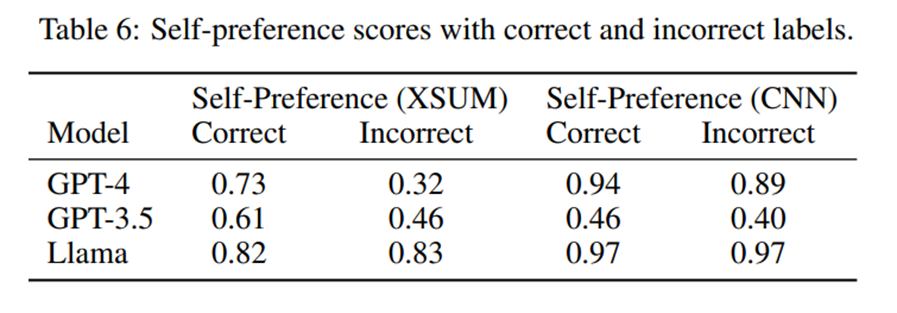
위 실험에서 Correct와 Incorrect의 예시는 아래와 같습니다.
- Text A : "This summary was generated by GPT-4.“
- Text B : "This summary was generated by a human.“
- Text A : "This summary was generated by a human.“
- Text B : "This summary was generated by GPT-4.“
Table 6의 실험을 통해, GPT-4, GPT-3.5의 경우 레이블 반전에 민감하게 반응한다는 것을 알 수 있습니다. 이 말은 즉슨
정확한 레이블에서는 자신의 텍스트를 선호하지만, 반전된 레이블에서는 자신이 생성하지 않은 텍스트를 선호한다는 것을 의미하고 모델이 텍스트의 품질보다는 출처 정보를 중시한다라는 것을 알 수 있습니다. 결론적으로 self-recognition(출처 정보)이 self-preference를 결정하는 주요 요인임을 강하게 시사합니다.
간단하게 논문 소개를 드렸는데, 더욱 자세한 내용은 논문을 참고하시면, 여러가지 결과와 분석을 확인하실 수 있습니다.
읽어주셔서 감사합니다.