본 포스팅은 Deep Convolutional Neural Network의 running time 최적화를 위해 channel level pruning을 도입한 "Learning Efficient Convolutional Networks through Network Slimming" (ICCV 2017)를 리뷰하도록 하겠습니다. 포스팅에 앞서, 주제와 관련된 모든 연구 내용은 Learning Efficient Convolutional Networks through Network Slimming을 참조했음을 먼저 밝힙니다.
History
Convolutional Neural Networks (CNNs)가 다양한 Computer Vision Task 처리에 중요한 솔루션으로 도입이 된 이후, 실제 응용된 어플리케이션에서 활용하려다 보니 Practical Issue가 광범위하게 발생하였습니다. 이들 중 실제 Light-weight device에서는 CNNs의 Computation Issue가 핵심적으로 보고되었는데요. 이를 해결하기 위해 Depp CNN Architecture의 발전은 Reinforcement Learning을 활용하는 수준까지 도달하였지만, 실제 응용되기엔 한계가 있었습니다. 이를 위해 다양한 경량화 기법들 즉, Weight Pruning이나 Filter or Channel Pruning과 같은 Model Reduction 효과를 극대화시키는 기술들이 소개되었고, 본 포스팅은 이 범주에서 Channel Pruning을 활용한 Reduction 효과에 대한 부분에 해당합니다.
Filter or Channel Pruning Effect
Pruning 기법은 모델 내부의 Node 간의 Weighted Sum으로 구성된 커넥션들 중에서 불필요한 커넥션을 제거하는 기술입니다. 이를 통해, 중요하고, 필요하다고 고려되는 커넥션의 구성으로 최소화 함으로써, 모델 축소를 극대화하는 효과를 볼 수 있습니다. 하지만, 커넥션을 구성하는 Weight Parameter들은 대체로 Matrix 형태의 정형화된 데이터 구조로 관리되는데, 상기 기술로 인해 메모리 최적화와 같은 부수적인 경량화 효과를 얻기 위해서는 Sparse Matrix를 변형하여 관리할 데이터 구조가 요구되었습니다. 이에 따라, Weight Pruning은 아직까지 일반적으로 사용하는 경량화 디바이스에서 효율적으로 Running하지 못한다는 지적이 있었고, 기존에 활요하는 데이터 구조를 충분히 유지하며 딥러닝 모델의 경량화를 극대화하는 방향의 연구가 논의되었습니다.
Filter 혹은 Channel Pruning은 Deep CNNs 구조에서 Computation이 가장 Dominant한 Convolutional Layer의 경량화를 목표로 하여, 이 Layer에 존재하는 Intermediate Feature Neurons의 개수를 최대한 줄이는 거시적인 관점에서의 Pruning을 의미합니다. 이 Pruning의 효과로는 기존의 Structured Data Structure를 그대로 유지하며, 이들의 개수를 제거하는 형태이기 때문에, 일반적인 디바이스에서도 경량화 효과를 충분히 느낄 수 있습니다.
Network Slimming
본 포스팅에서 언급하는 Network Slimming이라는 연구는 Intermediate Feature Neurons의 개수를 최적화하는 방법론을 제안한 논문이며, Architecture의 한계에 따라 사용 가능 여부가 결정되지만, 저의 주관으로는 최적화 파이프라인 구현을 위해 상당히 간단하고 Fancy한 접근이었다는 면에서 좋은 점수를 받지 않았나 생각합니다.
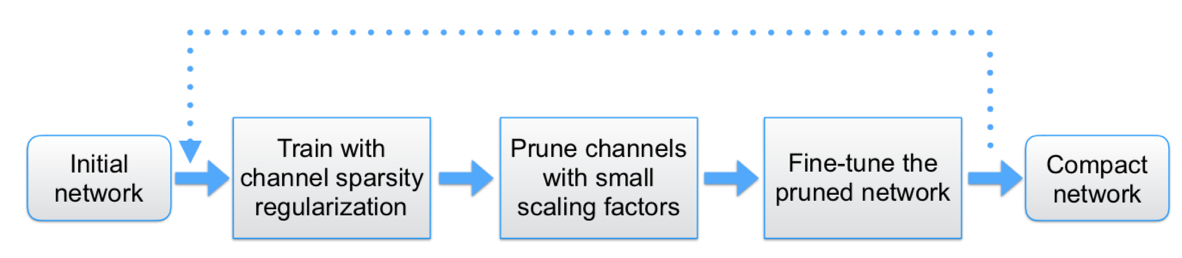
Network Slimming은 1) Deep CNNs의 학습 방식을 Stochastic Gradient Descent (SGD)를 활용하고 있고 이를 통해 Batch 단위 학습을 하고 있다는 점, 2) Layer 마다 Batch의 정규화가 요구되며 Batch Normalization Layer (BN)을 대부분의 네트워크 모델이 채택하고 있다는 점, 두 가지 측면을 Motivation으로 삼아 BN의 Trainable Variable인 Scaling Factor를 활용하여 Layer의 결과물인 Output Channel에서 불필요한 Channel을 찾아 제거하는 아이디어를 제안하였습니다. 이는 Scaling Factor가 학습 중인 시점에 Sparse 하게 되도록 L1-norm으로 Regularization을 하였는데요. 이 기법으로 인해 충분히 Channel 개수를 최적화하여 모델을 "Slim"하게 만드는 데 성공하였습니다.


Network Slimming
Network Slimming의 Pruning 파이프라인은 전체 모델 구조에 대하여 하나의 Pruning Ratio를 활용하여 Dynamic Layer-Wise Pruning으로 처리하였고, 이를 여러 횟수 반복하여 Fine Tuning하였습니다.
서술한 연구 내용 외에 추가적인 연구 결과나 이해가 필요한 부분이 있으면 직접 링크된 논문을 읽어보시고 댓글을 남겨주시면 답변드리겠습니다. 제가 작성한 PPT 자료를 업로드 해드리니 필요하시면 참고해주세요.