본 게시물은 김성훈 교수님의 모두의 강화학습 https://hunkim.github.io/ml/ 을 참고하였으며 "Playing Atari with Deep Reinforcement Leraning" , "Human-level control through deep reinforcement learning" 논문을 기반으로 제작했음을 알립니다.
Q-learning
Q-learning은 에이전트(agent)가 주어진 상태 (state) 에서 행동(action)을 취했을 경우 받을 수 있는 보상(reward)의 기댓값을 예측하는 Q 함수를 사용하여 최적의 정책(policy)을 학습하는 강화학습 기법입니다.
1. agent는 현재 환경(environment) 에서 특정 state s에 존재합니다.
2. agent가 action의 집합 A의 모든 action을 취했을 때의 rewards를 Q 함수로 구할 수 있습니다.
3. reward가 가장 높은 action인 policy를 취하고 agent의 state는 새로운 state로 업데이트 됩니다.
Q- learning에서 쓰이는 Q 함수는 다음과 같이 정의 할 수 있습니다.

learned value는 agent가 현재 state에서 다음 state로 가기 위해 action을 취할때 얻을 수 있는 보상을 나타내는 식입니다. 하지만 미래에 agent가 받을수 있는 reward를 100% 신뢰하는것이 아닌 discount factor로 제한을 두고, 그만큼 현재 state에서 받았던 reward도 고려하여 최종적인 reward 값을 계산하게 됩니다. 이것이 바로 old value가 식에 포함된 이유입니다. 이때 계산한 reward 값은 "Q-table"에 저장됩니다. Q table을 점진적으로 수정해나가는 반복절차를 통해 agent의 행동을 학습시킬 수 있습니다.
하지만 이러한 Q-learning은 실제로 실행시켜보면 잘 동작하지 않는 경우가 빈번합니다.
1. agent가 취할 수 있는 state의 수가 많은 경우, Q-table 구축에 한계를 가지게 됩니다.
2. 순차적인 sample data 간의 corelation으로 인해 학습이 어렵습니다.
3. 예측값 (target Y)이 제대로 예측을 수행한것인지의 여부를 비교하기 위한 정답(Y)이 변합니다.
위와 같은 이유로 Q-learning은 잘 동작 하지 않습니다. 이러한 Q-learning의 단점을 보완하기 위해 Q-learning 기반의 DQN (Deep Q Network)이 출현했습니다.
DQN
DQN은 CNN (Convolutional Neural Net) 을 이용하여 Q 함수를 learning 하는 강화학습 기법입니다. 이때 CNN layer를 깊게 하여 training을 할 때 Q value의 accuracy를 증대시키는 것을 목표로 하고있습니다.
DQN은 Q-learning의 한계점을 극복하기위해 다음과 같은 기법을 사용합니다.
1. Experience Replay buffer를 사용합니다.
2. Target Neural Net과 Predict Neural Net으로 네트워크를 분리합니다.
Experience Replay buffer를 사용하는 이유는 순차적인 sample data 간의 corelation을 해결하기 위함입니다. agent의 state가 변경된 즉시 훈련시키지 않고 일정 수의 sample이 수집 될 동안 기다리게 됩니다. 나중에 일정 수의 sample이 buffer에 쌓이게 되면 랜덤하게 sample을 추출하여 미니배치를 활용해 학습합니다. 이 때 하나의 sample에는 state, action, reward, next state가 저장됩니다. 여러개의 sample로 training을 수행한 결과들을 모두 수렴하여 결과를 내므로 corelation 문제를 해결 할 수 있습니다.
하나의 네트워크를 사용하면 계속 Target Q-value 값이 변경되므로 Target값이 변함을 막기 위해 Target을 output으로 도출하는 Target Neural Net과 Q-value값을 예측하는 Neural Net을 분리합니다. 이 때 2개의 네트워크는 weight parameter를 제외한 모든 것이 같은 네트워크로 정의합니다. 예측한 Q-value의 안정된 수렴을 위해 target Network는 계속 update 되는것이 아닌 주기적으로 한번 update를 시키는 것이 특징입니다.

아래는 DQN의 pseudo code 입니다.

training을 수행할 때의 Loss function으로는 아래와 같은 MSE를 사용합니다. 아래의 loss function와 psuedo code에서 볼 수 있듯이, 두개의 네트워크가 분리되어 있으므로 각 네트워크에서 사용되는 파라미터 $\theta$ 의 표기가 다른것을 확인할 수 있습니다.
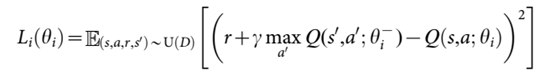
기술한 내용을 바탕으로 한 ppt 자료를 업로드 합니다.