안녕하세요. KDST팀 김유진입니다. 6월 14일에 진행했던 Image Editing에 대한 세미나 내용을 간략하게 요약해보도록 하겠습니다. 이번에 소개해 드릴 논문은 Text-to-Image model 기반의 Image editing 연구로 유명한 "Prompt-to-prompt image editing with cross-attention control", "Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation" 입니다.
Diffusion model기반의 Image editing을 수행하기 위한 방법론은 크게 3가지로 나눌 수 있습니다.
- Training-based: 모든 아키텍처를 training하여 target data distribution에 대해서 stable하게 학습할 수 있는 방법
- Testing-Time Finetuning-based: pre-trained diffusion model을 target data로 finetuning 하는 방법 또는 특정 identifier token의 embedding만을 optimize하는 방법
- Training and Finetuning Free-based: Source이미지나 target 이미지가 필요 없으며, low-cost로 image editing을 수행하는 방법

그 중에서도 오늘 소개해드릴 방법론은 3. Training and Finetuing Free-based Image editing 에 해당하는 연구이며, 그 중에서도 Text-to-Image diffusion model 기반의 image editing으로 유명한 P2P, PnP를 다룹니다.
(ICLR-2023, notable top-25%) Prompt-to-prompt image editing with cross-attention control
본 논문에서는 기존의 Text-to-Image model (DALLE, Imagen etc) 들은 일반적으로 source 이미지의 semantic information을 유지하며 세밀한 부분을 control하는것에 큰 어려움이 있음을 motivation으로 주장합니다.
또한 기존의 Image editing 방법론들은 masking 기법으로 수정하길 원하는 range를 heurisitic하게 정하여 원하는 부분만을 control 하는데, 이러한 방법론은 source image에 따라서 hand-craft 방식으로 mask를 지정해줘야하는 limitation이 존재한다고 주장합니다.
본 논문에서는 번거로운 기법 없이, Prompt상에서의 textual editing 만으로도 원하는 부분만을 수정할 수 있으며, 이는 Diffusion process에서 오직 cross-attention map을 변경해주는 연산만을 통해서 구현할 수 있음을 주장하고 있습니다.

P2P 논문에서는 위 그림과 같이 3가지의 경우에 대해서 image editing을 수행할 수 있다고 합니다.
1. Word swap: Source prompt의 특정 단어를 원하는 단어로 교체하는 경우
(ex: $P$=“a cat riding a bicycle” to $P^∗$=“a cat riding a car”)
Word swap 기법은 Gaussian distribution으로부터 random initalize된 동일한 image latent로부터 각 각 source prompt, target prompt로 이미지를 생성한 후, source prompt로부터 생성한 이미지의 cross-attention map을 target prompt로 생성한 이미지의 cross-attention map에 주입 (injection) 하는 방법입니다. 예를 들어, "A cat riding a bicycle" 이라는 source prompt에서 bicycle을 car로 editing을 수행하고 싶다면, "bicycle" 이라는 text에 해당하는 cross-attention map을 "car"에 해당하는 cross-attention map 으로 변경합니다. cross-attention map을 injection 하는 시점은, Diffusion의 denoising 스텝에서 특정 time step이 $tau$ 이하일 때에만 수행합니다.



특정 $tau$ 를 점차 T시점에서 에서 0 시점으로 옮길 때 editing 되는 이미지의 결과는 아래와 같습니다.

2. Prompt Refinement: Source prompt에 원하는 스타일의 prompt가 추가되는 경우
(ex: $P$=“a castle” to $P^∗$=“children drawing of a castle”)
Source prompt에 원래 존재했던 토큰들에 대한 cross-attention map은 유지한 채로, target prompt에서 새롭게 추가된 text에 대한 cross-attention map 만을 새로 주입하는 방법론입니다. Prompt Refinement를 수행하면, source image의 semantic information은 유지된 채로, 추가된 target prompt의 스타일만이 입혀지게 되는 효과가 나타납니다.

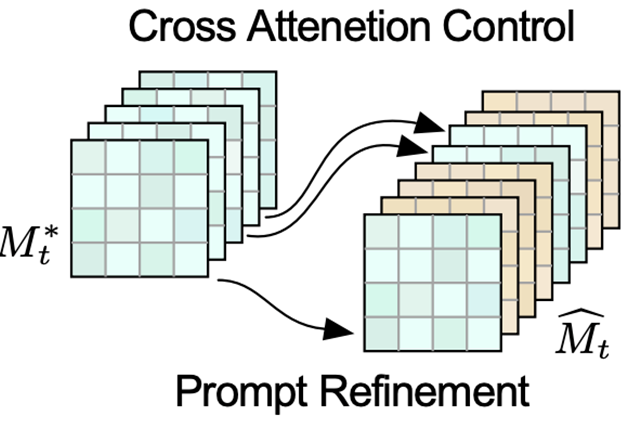


3. Attention Re-weighting: Source prompt의 특정 단어 영향력을 강화/약화하는 경우
(ex: $P$="The boulevards are crowed today")
Source prompt의 cross attention map에서 영향력을 바꾸고 싶은 text에 해당하는 cross attention map에 곱해지는 scale을 조정하며 image editing을 수행합니다. 이때, scale parameter c는 $c\in[-2,2]$ 제약조건을 따릅니다.




이처럼 prompt-to-prompt 방법론은 모델 아키텍처를 따로 training이나 fine-tuning 시키지 않고도 단순히 text editing과 그에 따른 Cross-attention map injection 연산을 통해, source image의 semantic information을 유지한 채, 원하는 스타일로 editing할 수 있음을 보입니다. 흥미로운 다른 결과들은 논문을 참조해주세요.