안녕하세요. KDST 박민철입니다.
오랜만에 인사드립니다. 그동안 연구하며 공부한 개념을 바탕으로 제가 몰입했던 다양한 딥러닝 연구 주제를 공유하고 소통하는 시간을 갖고자 합니다.
이번 공유 내용에서는, 딥러닝 모델을 배포하고 예측 모델로 활용할 때, 모델이 잘 학습했던 source 데이터와 target 데이터의 분포간 차이로 인해 예측의 어려움을 겪는 상황에서 target 데이터만으로 적응 (adaptation)되도록 지도하는 방법론 중 하나인 Test-Time Adaptation (TTA)에 관한 기술을 소개하겠습니다.
TTA는 모델이 배포된 시점, 즉 테스트 시점에 모델의 일부 파라미터를 fine-tuning하는 adaptation 기술입니다.
예를 들면, 테스트 데이터 즉 앞서 언급한 target 데이터는 실생활에서 예상할 수 있는 날씨 변화 (눈, 비, 황사, 등) 등이 포함되어 학습 시 관측 했던 데이터와 covariate shift가 존재할 수 있습니다. 이 때, 학습 데이터를 Maximum A Posteriori을 통해 최적화한 딥러닝 모델의 likelihood만으로 학습 데이터 분포로부터 멀리 shift된 데이터를 잘 추론할 수 있을 것이라 기대하기 어렵기 때문에, 기존의 likelihood는 잘 유지하면서, shifted 데이터에 대한 추가적인 정보를 모델의 파라미터에 반영하는 기술을 TTA라고 이해할 수 있습니다.
소개할 "TEA: Test-time Energy Adaptation, CVPR, 2024"는 테스트 시점에 covariate shift가 발생한 데이터 (ground truth를 알 수 없는 unlabeled target 데이터)를 바탕으로 Energy-Based Modeling (EBM)의 관점을 적용하여 배포된 모델의 일부 파라미터를 fine-tuning하는 방법을 제안합니다.

본 논문은 energy 분포 Boltzmann distribution을 데이터 x에 대한 분포 p(x)로 도입하고자 합니다.
이를 위해, JEM ("Your classifier is secretely an energy based model")에서 언급한 바와 같이 이미 학습된 discriminative 모델의 class별 logit을 사용하여, class에 대한 marginal을 바탕으로 EBM 기반의 x에 대한 분포를 나타냅니다.
EBM으로 표현하기 위한 energy (a.k.a. free energy)는 아래와 같이 정리되는데,

이를 통해, 우리는 p(x)를 모델의 free energy를 기반으로 EBM에 관한 분포로 아래와 같이 정리할 수 있고,

우리는 test 데이터라고 기입되어 있는 테스트 시점의 target 데이터를 배포된 모델에 대한 energy 기반의 Maximum Likelihood (ML) 문제로 생각하여 in-distribution 데이터로 유도할 수 있습니다. 이 과정에서, 분모의 evidence가 intractable하기 때문에 우회할 방법이 필요합니다.
먼저, ML에 대한 gradient를 고민해보면 Log-likelihood로 표현할 때, 다음과 같이 정리됩니다.


따라서, ML을 위한 gradient는 현재 모델이 in-distribution 데이터로 간주하는 일부 표본이 필요한데, 본 논문의 저자들은 Hinton 교수가 RBM 최적화에서 사용한 Contrastive Divergence를 목적함수로 도입하며, 기대값 추정의 부담을 덜게됩니다.
따라서, 저자들은 ML 문제를 아래와 같이 min-max 문제로 정의하고, target 데이터에 대한 in-distribution의 레퍼런스 데이터를 얻기 위해 Stochastic Gradient Langevin Dynamics (SGLD) 기반의 샘플링을 활용합니다.

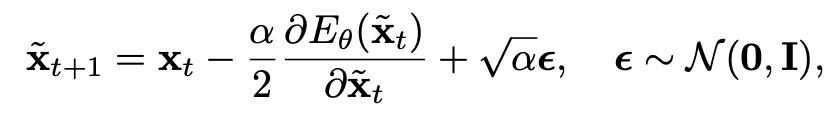
다음은 TEA기반의 TTA 알고리즘이며, 저자들은 학습의 효율성을 위해 normalization layer의 학습 파라미터만 업데이트합니다.

정리하면, 저자들은 배포된 모델을 EBM 기반으로 표현하여, 데이터에 대해 free energy를 부여함으로써, energy 크기에 따라 배포된 모델의 in-distribution 데이터와 out-of-distribution 데이터를 구분하고자 노력하였습니다. 테스트 시점에 covariate shift가 동반된 target 데이터의 energy를 in-distribution으로 추정할 수 있는 레퍼런스 데이터를 샘플링하여 Contrastive Divergence 기반으로 최적화함으로써, target 데이터를 EBM 관점에서 in-distribution로 포함시키고자 노력하였습니다.
본 논문은 Covariate shift에 대하여, TTA 방법들 중 normalization 방법론, pseudo label을 사용하는 방법론, entropy minimization의 방법론과 비교하였으며, in-depth 스터디로 1. energy 감소와 generalizability 개선 2. distribution에 대한 perception 그리고 generation 능력 3. calibration 개선에 대해 살펴보았습니다.
Experimental results

1. Correlation between energy reduction and generalizability enhancement

2. The distribution perception and generation capabilities


3. The distribution perception and generation capabilities

추가적으로 궁금한 부분은 논문을 참조 부탁드리며, 질문을 댓글로 남겨주시면 함께 고민할 좋은 기회가 될 것으로 생각합니다.
감사합니다.