안녕하세요, 학부연구생 박윤아입니다.
지난 4월에 처음으로 논문 리뷰 발표를 했었는데, 오늘 7월 21일 두번째 발표를 하게 되었습니다.
이 논문의 핵심 아이디어는, Attention Similarity Knowledge Distillation (A-SKD)로 Teacher model의 attention map을 student model로 전달하여, 저해상도 이미지에서도 얼굴인식 성능을 내도록 하는것 입니다.
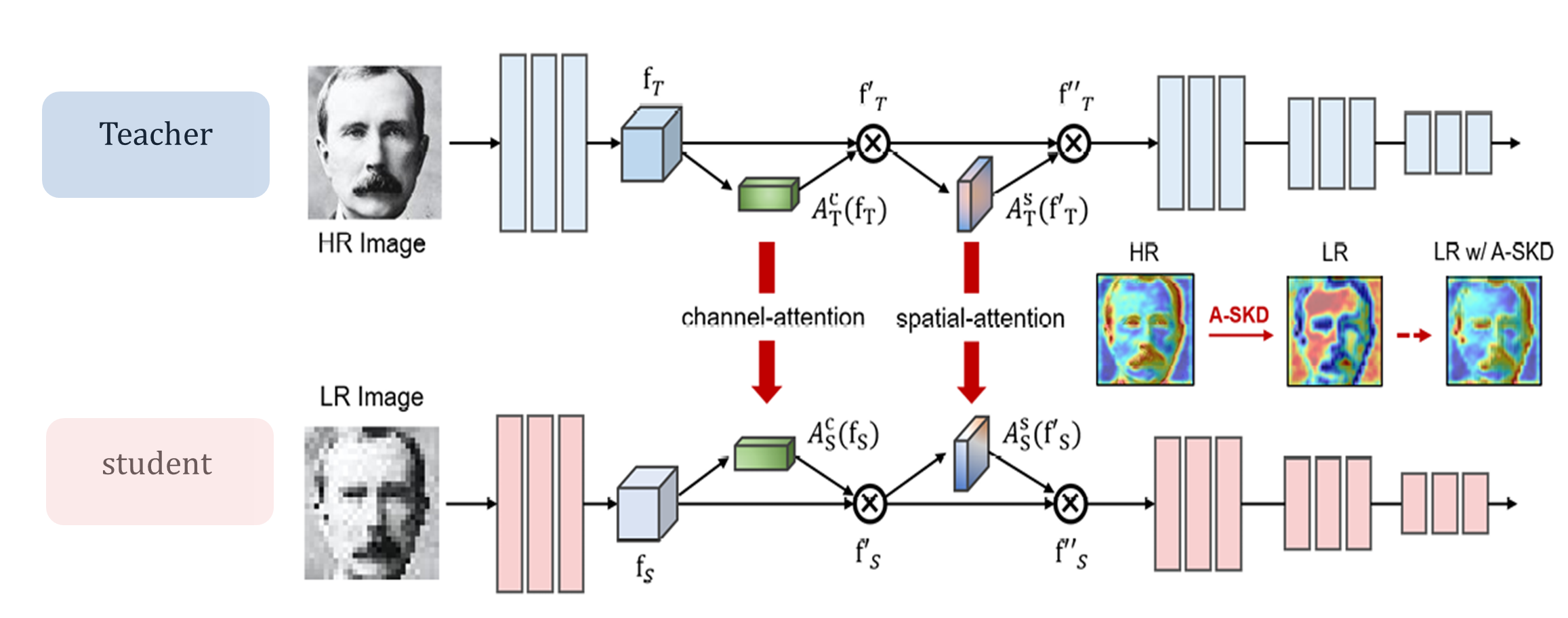
attention map을 distillation할 때 '고해상도 모델의 channel과 저해상도 모델의 channel의 역할(혹은 파라미터)가 다를텐데, attention map을 바로 전달해도 되는건지' 에 대해 질문하셨는데, 답하지 못했습니다.
논문에서 CBAM attention module을 사용했다고 나와있는데, 이 논문을 통해 실마리를 얻을 수 있을것 같아 공부해볼 예정입니다.
[31] Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: CBAM: Convolutional Block Attention Module. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 11211 LNCS, 3–19 (jul 2018), http://arxiv.org/abs/1807.06521
A-SKD의 loss는 다음 두가지 term으로 이루어집니다. 그 중 arcface loss에 대해 자세히 다루어보려고 합니다.

arcface loss는 addictive angular margin loss라고도 불리는데요, 각에 margin term을 추가하여 feature와 class 중심 사이의 각도가 충분히 줄어들도록 학습하게 됩니다.
자세한 과정은 다음과 같습니다.(민수님이 이해에 도움을 주셨습니다 감사합니다!)
아래 식에서 j가 정답 class 일때 log~ 식은 1에 가까워지도록 학습됩니다.
그러면 s* cosine θ _j 의 값은 0에 가까워지고 θ _j는 커집니다. 그래서 input feature와 정답이 아닌 class의 대표벡터(W_j)간의 각도가 커집니다. 그러면 그 영향으로 intra class간의 각도가 작아집니다.

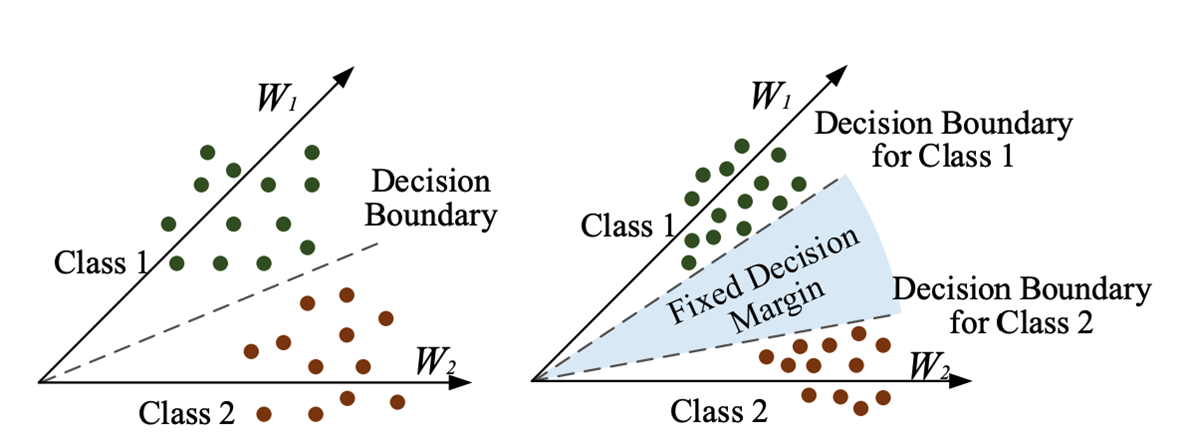
여기에서 클래스마다 같은 m값을 사용하는것이 맞는지, 그렇다면 intra class들의 거리가 줄어드는것이 맞는지에 대해 질문하셨습니다. 유진님께서 m은 360/class개수로 사용된다고 답변해주셨습니다.
실험결과
