오늘 소개드릴 논문은 "Zero-shot Adversarial Quantization"으로 CVPR 2021에 oral paper로 accept된 논문입니다. 해당 논문을 참조하시려면 논문링크와 github을 참고해주세요
- 관련논문
Overview
- 양자화 논문이지만 새로운 양자화 방법론이 아닌 새로운 fine-tuning방법론을 제시합니다.
- 매우 낮은 비트( < 8bit)로의 양자화는 정보 손실이 크기 때문에 정확도 보정을 위해 fine-tuning이 필수적입니다. 하지만 Fine-tuning에는 training-set이 필요합니다.
- Fine-tuning에 필요한 데이터를 generative model을 이용하여 생성, 생성한 데이터를 이용하여 Fine-tuning을 진행합니다. 매우 낮은 비트로의 양자화에서 SOTA 정확도를 달성하였습니다.

Introduction

- W*A* : weight 양자화 비트, activation 양자화 비트
- RQ : fine-tuning을 진행하지 않았을 때 정확도
- 위의 표를 보면 알 수 있듯이 매우 낮은 비트( < 8bit)로의 양자화는 정보 손실이 크기 때문에 정확도 보정을 위해 fine-tuning이 필수적입니다.
- 하지만 개인정보, 보안등의 이유로 기존 학습 데이터에 접근이 불가능한 경우가 종종 존재합니다. 따라서 Data-free quantization에 대해 다양한 연구가 진행되어 왔습니다.
- 본 논문에서는 생성모델을 이용하여 데이터를 생성, 생성한 데이터를 이용하여 양자화 모델에 fine-tuning을 진행하여 매우 높은 정확도를 보였습니다.
Background
- 개인정보 보호와 법적인 문제에 따라 서버추론이 아닌 온디바이스 추론의 요구가 점점 증가하고 있습니다.
- 기존의 무겁고 정확한 모델을 온디바이스 추론이 가능하도록 경량화 하는 기법 중 하나가 바로 양자화(Quantization) 방법론입니다.
- Deep Compression논문에 따르면 45nm CMOS공정의 경우 부동소수점 덧셈에 0.9pJ, 32bit SRAM cache 접근에 5pJ이 소비되는 반면 32bit DRAM memory접근에는 무려 640pJ이 소비된다고 합니다.
- 부동소수점으로 되어 있는 딥러닝 모델을 INT8, INT6등으로 양자화를 진행한다면 DRAM memory접근하는데 소비되는 에너지를 획기적으로 줄일 수 있기 때문에 양자화는 가장 흔히 사용되는 경량화 기법 중 하나입니다.

- 양자화는 [그림 2] 같은 과정을 매 레이어마다 진행합니다.
- Input Feature Map을 원하는 비트로 양자화 (위의 그림의 경우엔 INT8)
- 이미 양자화 되어 있는 weight (위의 그림의 경우엔 INT8)와 연산을 진행합니다.
- 계산 결과를 Float32로 변환합니다. (Dequantization)
- 이때, 이전 레이어의 Dequantization scale factor와 다음 레이어의 quantization scale factor를 알고있다면 두 scale factor를 곱하여 dequantization과정을 생략할 수 있습니다. 이를 Requantization이라 합니다.([그림 3] 참고)


- [그림 4]를 보시면 양자화에 대한 직관적인 이해를 할 수 있는데요. weight 또는 activation의 최솟값이 (INT8 양자화의 경우) -128에, 최댓값이 127에 매핑되는 것을 보실 수 있습니다. 이에 대한 자세한 수식은 다음과 같습니다.

q : quantization value
S: Scale factor
v : full-precision value(fp32)
Z : zero point(offset)
Related Work
DFQ
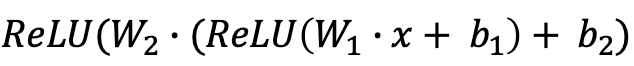

- 양자화는 weight 또는 activation의 최솟값 및 최댓값을 양자화된 값의 최소, 최대로 대응시키는 작업입니다. 만약 최솟값, 최댓값의 차이가 매우 크다면 정보 손실이 매우 클 것이고 이는 필연적으로 정확도 하락으로 이어지게 됩니다.
- 실예로 MobileNet-V2의 경우 per-layer 양자화를 진행할 경우 정확도가 1%가 됩니다.
- DFQ는 이를 보정하기 위한 방법론으로 ReLU 활성함수에서는 상수 배가 보존된다는 것을 이용하여 ([수식 2, 3] 참고) weight의 스케일을 맞춰준 후 양자화를 진행하는 방법론입니다.
- 하지만 fine-tuning이 없기 때문에 매우 낮은 비트로의 양자화를 진행할 경우 정확도 손실이 크다는 단점이 있습니다.
ACIQ
- backround에서 설명드린 방법으로 양자화를 진행할 경우 중요한 정보, 중요하지 않은 정보(outlier)가 동일하게 양자화가 됩니다.
- ACIQ논문에서는 outlier를 제거하는 방법론을 제시하여 outlier를 제거한 후 양자화를 진행하여 정확도를 보정하는 연구입니다.
- DFQ와 같이 fine-tuning작업이 없기 때문에 매우 낮은 비트로의 양자화를 진행할 경우 정확도 손실이 불가피합니다.
ZeroQ
- 데이터를 생성한 후 생성한 데이터를 이용하여 fine-tuning을 진행하는 연구입니다.
- DeepInversion(자세한 내용은 링크 참고)과 같이 input space(image)를 업데이트하는 방법으로 데이터를 생성합니다.
- input space(image)를 업데이트하는 손실함수는 BatchNorm statistic loss를 사용하는데, 이는 input feature map의 평균과 분산을 batchnorm layer가 가지고 있는 평균, 분산과 동일하도록 학습을 진행하는 손실함수 입니다.
- 학습된 모델의 BatchNorm layer가 가지고 있는 running mean, running variance는 학습데이터를 이용하여 구한 값이지만 데이터셋전체에 대한 값이기에 모든 학습 데이터를 커버하기엔 부족하다는 단점이 있습니다.
GDFQ
- ZeroQ와 같이 데이터를 생성한 후 생성한 데이터를 이용하여 fine-tuning을 진행하는 연구입니다.
- ZeroQ와 다른 점은 input space(image)를 업데이트하는 것이 아닌 생성모델을 이용하여 데이터를 생성합니다.
- 손실함수가 ZeroQ와 매우 유사하게 BatchNorm Statistic loss를 사용하기때문에 ZeroQ와 동일한 단점을 가지고 있습니다.
Proposed Method
- 본 논문에서 제안하는 zero-shot adversarial quantization(ZAQ)에 대해 알아보겠습니다.
- 본 논문의 주아이디어는 다음과 같습니다.
- 기존 모델(P)와 양자화 모델(Q)간의 차이가 적다면, Q는 잘 양자화 된 모델이다.
- P와 Q간의 차이를 줄이는 방향으로 fine-tuning을 하면 Q는 잘 양자화 된 모델이 된다.

- ZAQ의 pipeline은 굉장히 간단합니다.
- 양자화 모델 Q를 생성합니다.
- 생성모델(G)는 P와 Q간의 차이를 극대화 시키는 방향으로 데이터를 생성합니다.
- G가 생성한 데이터를 이용하여 Q는 P와의 차이를 줄이는 방향으로 fine-tuning을 진행합니다.
- pipeline의 2와 3이 반대되므로 Adversarial이라 할 수 있습니다. 이를 목적함수(손실함수)로 자세히 살펴보도록 하겠습니다.
- 생성모델 손실함수는 다음과 같습니다.

- [그림 5]를 참고하면 알 수 있듯이 Do는 P와 Q의 출력의 불일치를 의미합니다.
- Df는 P와 Q의 inter featuremap간 불일치를 의미합니다.
- 즉, P와 Q의 출력 및 inter featuremap간 불일치를 증가시키는 방향으로 생성모델의 학습이 진행됩니다.
- 하지만, P와 Q간 불일치만 증가시키는 방향으로 학습을 진행할 경우 생성모델은 fine-tuning에 도움이 되지 않는 데이터를 생성해 낼 수도 있습니다. 따라서 저자들은 아래와 같은 Regularizer term을 추가하였습니다.

- Fine-tuning 손실함수는 다음과 같습니다.

- 양자화된 모델 Q는 P와의 불일치가 적을수록 좋은 모델입니다. 따라서 Do(output 불일치 정도)와 Df(inter featuremap 불일치 정도)를 모두 최소화 시키는 방향으로 fine-tuning을 진행합니다.
- 생성모델은 P와 Q간의 차이를 극대화 시키는 방향으로 어려운 데이터를 생성하고, 생성된 어려운 데이터에 대해 P와 Q의 차이를 줄이도록 Q가 학습을 진행합니다.
- Loss function detail
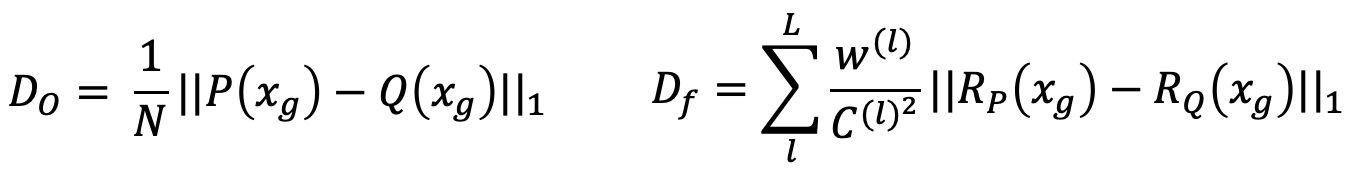
- Do는 P와 Q의 output의 L1 norm을 통해 구합니다. (N은 output node 개수)
- Df는 P와 Q의 inter feature map간의 L1 norm을 통해 구하는데, 여기서 주의해야 할 것은 P는 full-precision 모델, Q는 양자화 모델입니다. 즉, P와 Q는 inter feature map의 자료형이 다르므로 L1 norm을 direct하게 구할 수 없습니다.
- 때문에 저자들은 CRM(Channel Relation Map)을 제안합니다.

- Inter feature map을 channel-wise하게 1차원으로 펼친 뒤, 자신과의 dot product를 통해 cosine similarity map을 구합니다. 이는 style-transfer에서 사용하는 gram matrix와 굉장히 유사한데, 차이점이 있다면 gram matrix는 배치사이즈를 고려하지 않은 채 1차원으로 펼친 뒤, cosine similarity map을 구하지만 CRM은 배치사이즈를 고려하여 channel-wise하게 1차원으로 펼친 뒤 cosine similarity map을 구합니다.
- P와 Q의 inter feature map의 CRM을 각각 구한 뒤, CRM의 L1 norm을 통해 Df를 구할 수 있습니다.
- inter feature map은 매 레이어마다 존재하므로 저자들은 매 레이어의 산술합이 아닌, 가중합을 통해 최종적으로 Df를 구하는데 매 레이어의 가중치에 대한 식은 [수식 7]과 같습니다.

- CRM의 L1 norm을 모든 레이어에 대해 softmax를 취하여 weight를 구하고, 이를 매 에폭마다 누적하여 계산합니다.(EMA: Exponential Moving Average)
Experiments
- Classification Task

- 관련연구들에 비해 높은 정확도를 보이는 것을 확인할 수 있습니다. 2bit라는 매우 낮은 비트에 대해서도 준수한 정확도를 보입니다.
- Detection Task
- Dataset : VOC2012 (20 classes, 11,540 images)
- Model : SSD (Backbone is MobileNet-V2)
- Evaluation Metric : mAP (higher is better)

- Detection task또한 관련연구에 비해 높은 정확도를 달성한 것을 확인할 수 있고, real data를 전혀 사용하지 않았음에도 FT(Use original training set to fine-tune)에 필적하는 성능을 달성하였습니다.
Conclusion
- original data에 대한 접근이 전혀 없음에도 굉장한 성능을 내는 것이 놀라웠던 논문이고, CRM이라는 새로운 개념을 제시하여 output만 일치시키는 fine-tuning이 아닌, inter feature map또한 일치시키도록 하여 높은 정확도를 달성했다는 점이 재밌었습니다.
- 이상으로 "Zero-shot Adversarial Quantization" 논문 리뷰를 마치겠습니다. 감사합니다.