안녕하세요, KDST팀 이원준입니다.
진행하였던 논문 세미나 내용 간단하게 전달드리겠습니다.
본 논문의 Contribution은 다음과 같습니다
- LM이 스스로 external tool을 쓰도록 학습할 수 있게 한다.
- 언제, 어떻게, 어떤 API를 사용할지 스스로 결정할 수 있도록 한다.
- Self-supervised 방법을 통해 다양한 tool들의 적절한 사용 방법 학습하도록 한다.
논문에서 지적하는 기존의 LLM들의 몇가지 한계들은 다음과 같습니다.
- 날짜 기반에 대한 최신 정보에 액세스할 수 없음
- Hallucination
- 비교적 학습이 덜 된 언어에 대한 어려움
- 정확한 수학적 계산을 수행할 수 있는 수학적 기술의 부족
- 현재 시간에 대한 부족한 이해
이러한 한계들을 극복하기 위해 가장 간단한 방법은 검색 엔진, 계산기 또는 달력과 같은 외부 도구를 사용할 수 있는 기능을 제공하는 것입니다. 그러나 기존 접근 방식은 많은 양의 Human Annotation에 의존하거나 task-specific한 설정에만 도구 사용을 제한하여 LM에서 도구 사용을 광범위하게 사용하지 못한다는 단점이 존재합니다.
따라서, 본 논문에서는 Toolformer를 제안함으로써 기존의 LM의 한계와 기존의 접근 방식에 대한 새로운 방향을 제시합니다.

Toolformer는 크게 3단계로 이루어집니다.
-
Sample API Calls : 모델이 텍스트에서 특정 위치를 선택하고 해당 위치에서 가능한 API 호출을 추출하는 과정
- Execute API Calls : 샘플링된 API 호출이 실제로 실행되는 과정
- Filter API Calls : 실행된 API 호출 중 텍스트 내 다음 토큰 예측에 도움이 되는 호출만 필터링하여 선택

API call에 대한 예시는 위 사진과 같습니다.
Sample API calls 단계에서는

위 식을 통해 입력 시퀀스에서 API가 𝑖 위치에서 호출될 확률을 계산합니다. 이렇게 계산된 모든 위치에 대한 확률 중 일정 Threshold를 넘는 위치만 선택적으로 API call을 수행하게 됩니다.
Filter API calls 단계에서는
각각에 위치에서 호출되었을 때의 loss 값을 계산하여 Filtering을 진행하게 됩니다.


L+ : API 호출과 그에 대한 Response가 모두 제공되는 경우의 손실
L- : API 호출이 이루어지지 않거나 API 호출만 제공되는 경우 중 최솟값

결론적으로 두 Loss의 뺀 값에 Threshold보다 높으면 해당 위치를 API를 호출하기에 적합한 위치라고 판단하는 과정을 진행하게 됩니다.
실험 결과 파트는 아래와 같습니다.

사용되는 모델은 기본적으로 GPT-J 모델을 채택하였으며 데이터 셋은 CCNet을 사용하였습니다.
논문에서는 C로 표기하며 C*는 API call이 포함된 데이터셋을 의미합니다.
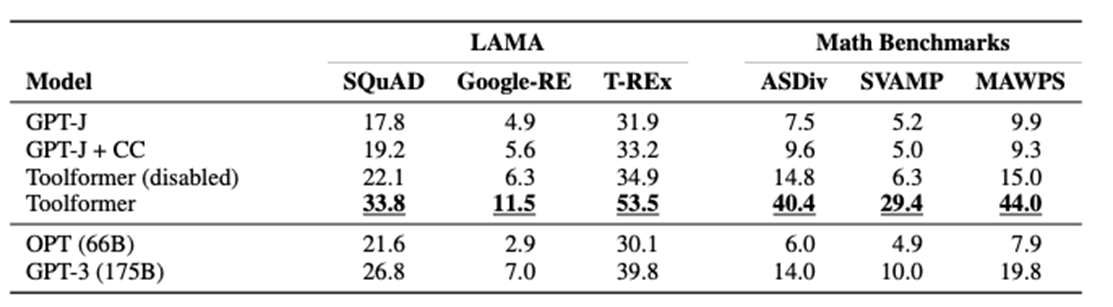


실험 전반적으로 Toolformer 방법론을 통해 학습된 모델이 우수한 성능을 보이고 있으며, 더욱 자세한 실험 결과와 분석에 대한 내용은 논문을 참고해주시면 감사하겠습니다.